
This is the first article in a new series where we uncover how we do things in the tech department at Shoprocket. We’re proud of the systems and processes we have in place, but we’re always looking to improve and develop. So we’d love to hear how you do things.
Today, we’re going to take a look at how a sprint is set up at Shoprocket.
We run a 10-day sprint process. Here’s what an average day looks like for one of our developers:
- 4 hours sprint
- 2 hours bug fixing
- 2 hours free time
That means that each developer has 40 hours a sprint to work on their sprint tasks. Each hour equals one story point and these are broken down in the following manner:
Story Size
- small = 5 story points
- medium = 10 story points
- large = 20 story points
- extra large = 40 story points
We use story points to control our burndown and estimated deliveries. We never promise a delivery date as humans are just terrible at doing this. In the future, we plan to use the metadata in our sprint tool and bind this to the story size to work out historical averages as to how long it took to do X as it is a good indicator how long it will take to do similar tasks. We do not have this tool yet, though, so if someone would love to build it (I am looking at you sprint.ly) that would be awesome.
In this sprint, it was a very vanilla affair. We started off fixing bugs and writing system updates as per usual.
One such update was to order reporting. By offering line item support, users can now see what an order is made up of instead of just seeing the order total. On the surface, this seems like a very simple thing to do, but in reality, it’s quite tricky as the report has to be built in such a way as to be compatible with the myriad of accounting packages out there. Additionally, it has to work with our entire database going back a full year and export a full report in real time in approximately one second.
As far as the core tech goes, Winston has been working on splitting off our first microservice and integrating it with our existing application. The one we chose initially was a Session Management System which is the code that generates a unique GUID used for the life of an order (be it completed or abandoned). We are going to write a whole series on our microservice adventure so we will not go into too much detail here, suffice to say that moving from monolithic to microservice is challenging but fun.
Alex has been working on a back-end tool to deal with UTM’s. Marketing has been pushing for this tool for a long time and we are amazed that something like this does not currently exist in the wild (we will probably open source it once it’s complete) as it is a relatively simple and much-required tool.
Shashi has been on fire this week. He has wrapped up his gift wrapping module, which is with product now and essentially allows you to very quickly add gift wrapping options to your cart. After that, he quickly moved onto building our Google Analytics integration. Now this is something that was not on our radar at all, but one of our partners came to use requesting it, telling us how important it was to their product life cycle. Being the accommodating tech-team we are, we squeezed it in. It is already looking cool and tracks all the major elements of the a shopping cart effortlessly. We never really deviate from a sprint once it is set but we do leave the flexibility in the sprint to be able to do so.
Here’s what one of our Sprint.ly tasks look like.
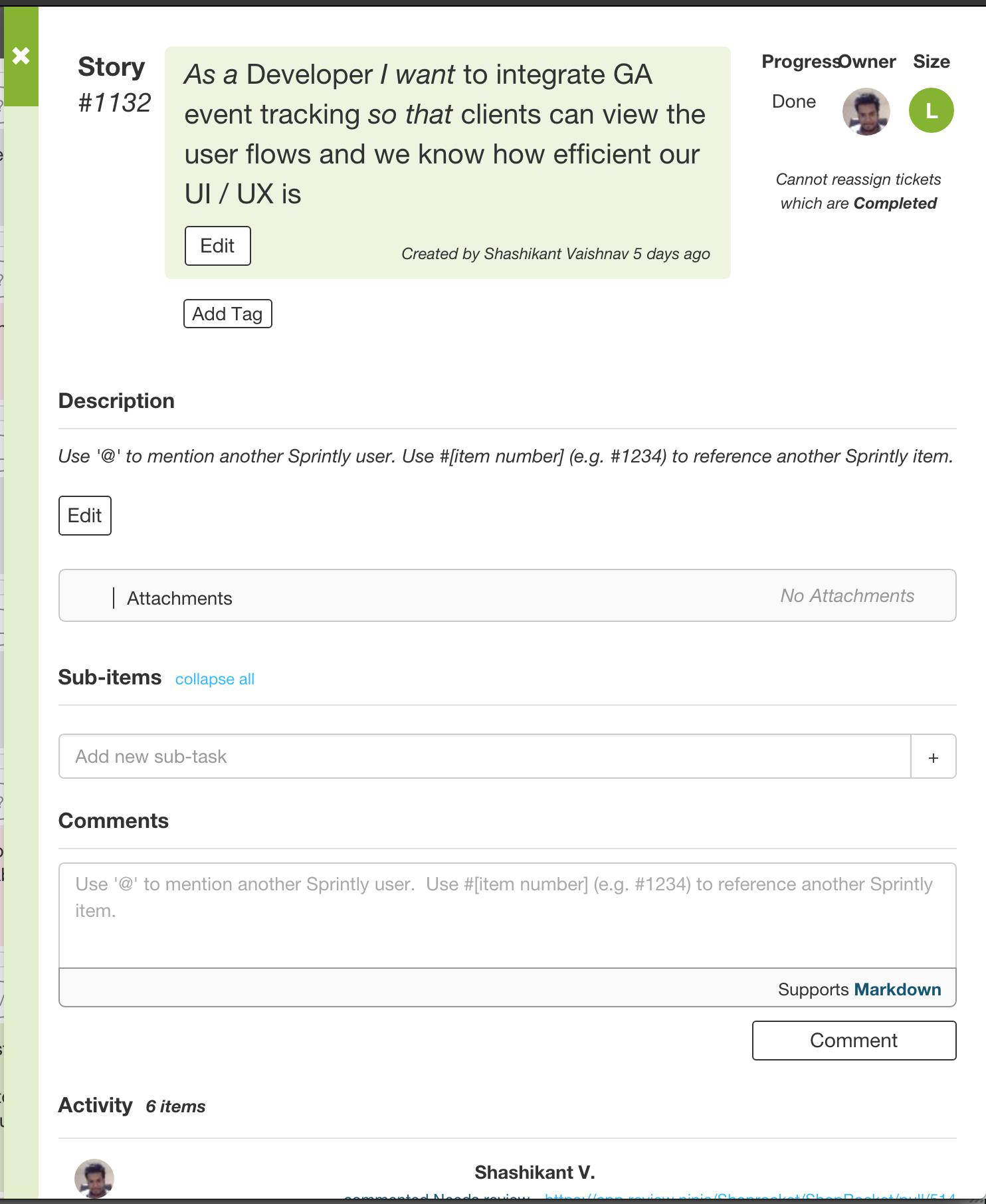
The process for the creation of these is also pretty simple: someone who takes the lead writes the initial spec and then we all jump on a Google Hangout and flesh it out. It is then sent to any external parties for feedback and sense checked by the rest of the company.
And then we build it. Simple, huh?





